
The Official Open Data Science March Madness Bracket
By
George McIntire
Last week was the most exciting event in sports, that’s right I’m talking about the NCAA Basketball Tourney aka “March Madness.” And we here at Open Data Science have totally caught March Madness fever and have decided to try our hand at making a bracket of predictions.

Since we’re in the business of data science, we’ll be employing algorithms, hard data, and a scientific method in our predictions instead of gut feelings and superstitions. In this article we’ll go over the process of creating our model and our approach.
Data Wrangling/Transformation
The dirty open secret of data science is that despite being the “Sexiest Job of the 21st Century,” the majority of jobs involves data cleaning, which at best is boring and at worst is the equivalent of trying to untangle a thousand headphones while blindfolded. And this rule was certainly true for this project.
Like most data scientists who make march madness predictions, I used data from Kaggle’s March Madness competition. Acquiring the data was the easy part, but the transformation was what occupied the majority of the time spent on this project.
First Step:
My first course of action was to create a dataset of each team’s regular season stats. This means a dataset where each row is a team, the year of the season, number of wins, and average of stats such as points per game, assists per game, etc.
In the Kaggle data, there’s a dataset of detailed stats for regular season games from 2003-2016. Each row represents a game, and the columns include information such as team ids, points for each team, number of rebounds, assists, and other stats. In a painstaking process, I created a new dataset of teams and their stats for a given season and I did this for every season from 2003-2016.
Second Step:
Next I had to combine my new dataset of season stats with the Kaggle dataset of NCAA tournament results. To do this, I had to join the two different datasets on the team ids and seasons.
I obviously used more stats than points per game, but you get my point.
Third Step:
At this point, my dataset was pretty close to being finalized, but there were some important tasks I needed to take care of before I could begin the modeling.
For a project like this, the target variable is obvious, it’s predicting whether or not a team will win. But I needed to choose which one of the two teams I am predicting to win. To make things, I decided I would try to predict team 1’s results. My target variable would be a column of 1s or 0s, 1 if team 1 won and 0 if they lost.
After this part, I had to do some further engineering. Including stats for both teams gave my data excess data and noise, so my solution was to subtract team 2’s stats from team 1’s stats. This action almost halved the number of features without losing any of the value of the data.
Fourth Step:
Even though I had a machine learning ready dataset, I wasn’t satisfied with my selection of features. The data was missing important features such as conference, strength of schedule, and whether or not a team won their conference tourney.
This data that I wanted wasn’t available via Kaggle, so I had to acquire it on my own, a task so arduous I almost gave up on it.
To sum it up, I scraped data from the college basketball section of Sports-Reference.com and had to laboriously combine it with my dataset. This involved a lot of manual tweaking and hard coding, I’ll save you the gruesome details but trust me, this was not fun at all.
Once I overcame that monumental feat, I applied the same feature engineering technique that I used for the season stats (subtracting the team 2’s features from that of team 1.)
At long last, I had my finalized dataset. Here are my features (every attribute is the difference between team 1 and team 2’s):
Wins, tournament seeding, points per game, assists per game, three pointers per game, rebounds per game, turnovers per game, steals per game, strength of schedule, member of big conference (ACC, Big 10, SEC, etc…), conference tourney champion, SRS (simple rating system).
Modeling
Model selection and training.
After my crash course in data cleaning and transformation, I had never been so happy to execute the modeling section of a data science project.
I followed the standard procedure for deciding on which model to use for my predictions. My initial set of algorithms was comprised of Logistic Regression, K-Nearest Neighbors, Decision Trees, Gaussian Naive Bayes, and a Gradient Boosting Classifier.
My null accuracy for the data was 50% (meaning half the time, team 1 won). However I didn’t feel as though this was the “true” null accuracy. In the data, I observed that the team with the lower seed (lower means better) won about 70% of the time, so I decided 70% was a better null accuracy score.
My job was to devise a model that made predictions with an accuracy better than 70%.
After thorough testing of each of the algorithms, Gradient Boosting was the clear winner of the bunch, which didn’t come as a surprise to me. It produced a cross-validated accuracy score of 75.7%, an almost six percentage point increase from the null accuracy. It’s not as high as I had wanted, but in my opinion still a significant enough performance.
Initial Predictions
Now came the fun part of making the predictions. I submitted my bracket predictions to Yahoo! Sports’ Tourney Pick’Em competition.
But before I could make the predictions, much to my chagrin, I had to do one last round of data wrangling, this time for the 2017 data (the testing data). This step was pretty difficult but not as bad as the data transformation for the training data.
With the creation of my testing set, I was finally ready to make my picks. Choosing a winner was pretty straightforward, if the model spit out a “1” then I chose team 1 to advance and if it chose a “0” team 2 would advance.
After entering my predictions, I looked at my completed bracket and felt unsatisfied.
My model yielded a very conservative bracket. My Final Four picks were all number one seeds and the lower seed team won 90.5% of the time. The model produced very few upsets because it defaults to choosing the team with the higher probability every time. So in cases where you’d expect some upsets such as 6-11 or 5-12 seed matchups, the model chose the lower seed each time because it had a slightly higher chance of winning. For a competition infamous for upsets, my initial model was shown to be inadequate.
Model Revamp
My solution for this problem was to create a second model, a model with only one feature: difference in seeding between the teams.
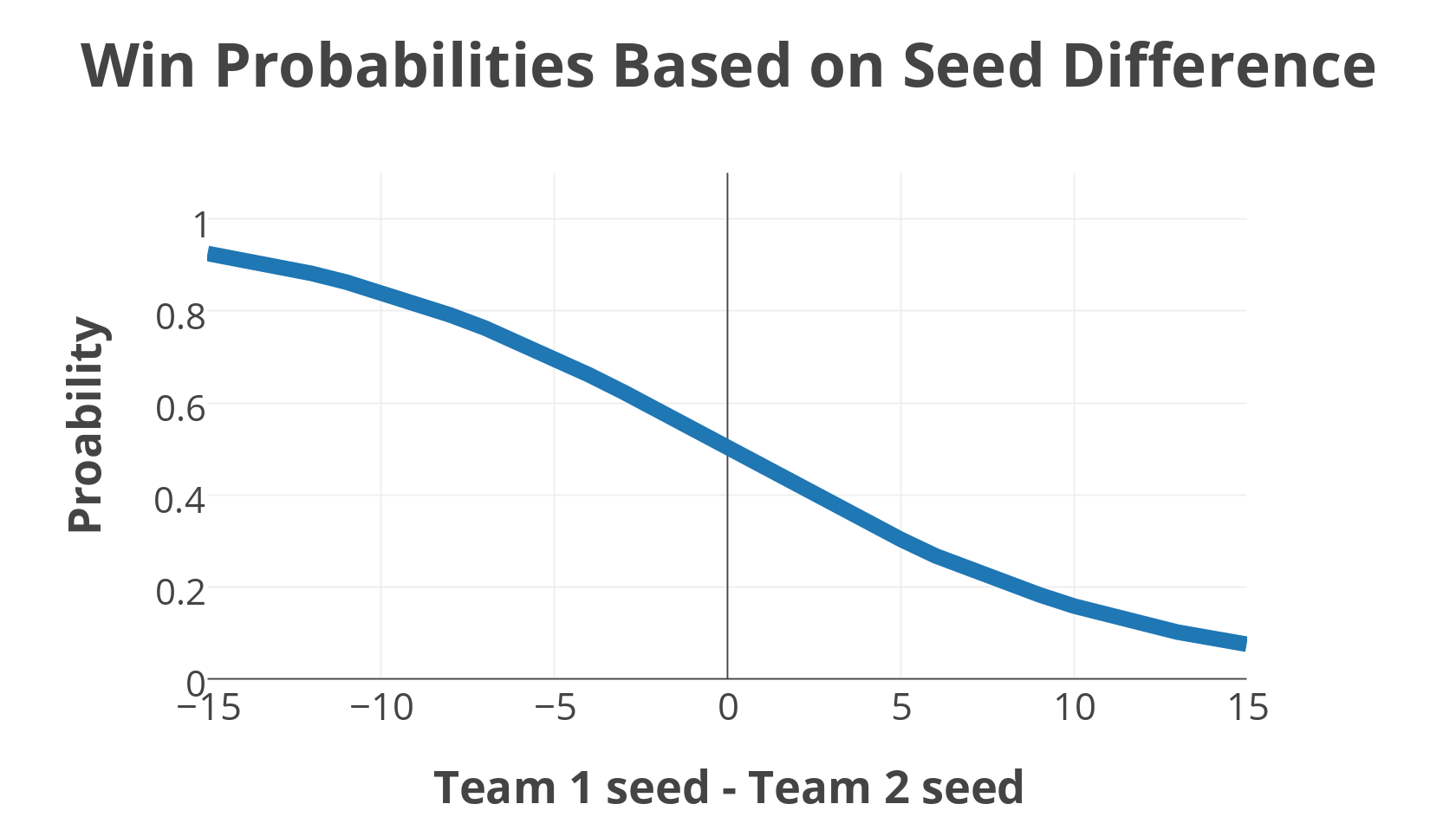
I trained a logistic regression model to predict the outcome of a game based on the difference of seeding. This didn’t produce a very good model obviously, but that wasn’t the point. The reason why I used a logistic regression was to derive the predicted probability of an outcome. So if the difference between Team 1’s seed and Team 2’s seed was -13, then the model output a high probability of Team 1 winning.
The following chart displays the probabilities as a function of the seed difference.
Here’s how I incorporated this new model into the predictions made by my original model.
I made my decision to choose which team will win a given matchup based on whether or not the main model’s probability of the lower seeded team winning was equal or greater than the probability of that team winning generated by the seed difference model.
For example, if my main model says that a 2 seed team has a 78% chance of beating a 7 seed team and the seed difference model says there’s a 69% chance of that happening, then I choose the 2 seed team to win. But if my main model said that the 2 seed team had a 65% chance of winning, then I chose the 7 seed team to advance in the tournament. And in cases where the seeds were equal, I wouldn’t need to use the seed difference model. This second model provided me a tool of yielding the threshold with which to base my decisions on.
Final Predictions
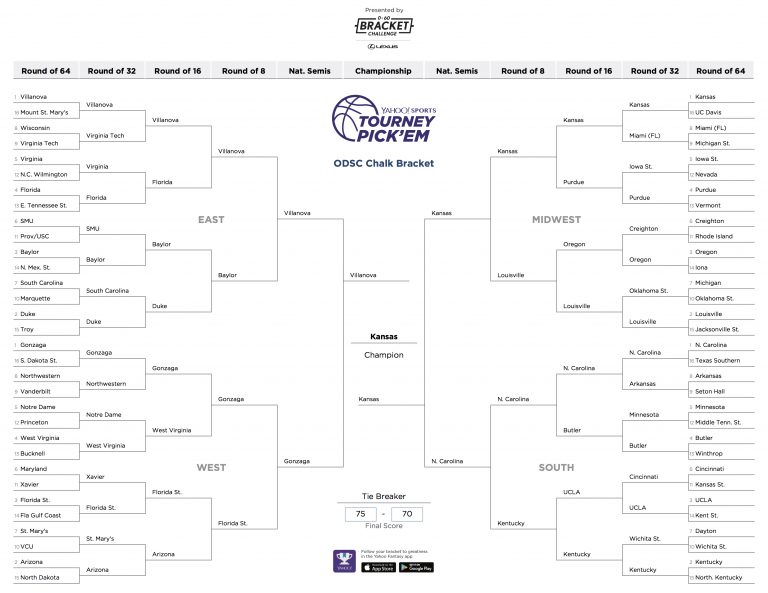
I created a new bracket with predictions made on my new dual-model system and came away feeling much better about my results. This new bracket looked a lot like a typical March Madness bracket.
I present the official Open Data Science 2017 March Madness Bracket.

My modeling system produced a bracket where the lowered seed wins 70% of the time, which as you may recall is the same score as the historical average. This gives me a lot of confidence in my model.
What does concern me and also excites me is the picking of 11-seed Xavier and 10-seed Wichita State in the Final Four. In the history of the tournament there has never been more than one double-digit seed team in the top four. Three 11-seeds have made the Final Four, while no 10-seeds have advanced to this stage. FiveThirtyEight gives Xavier a less than 1% chance of making the Final Four while giving Wichita State an 8% chance. So FiveThirtyEight is basically saying that there is absolutely no chance of those two teams both making the Final Four.
George McIntire is a journalist turned data scientist/journalist hybrid.


